AddMissingIndicator#
The AddMissingIndicator() adds a binary variable indicating if observations are
missing (missing indicator). It adds missing indicators to both categorical and numerical
variables.
You can select the variables for which the missing indicators should be created passing
a variable list to the variables parameter. Alternatively, the imputer will
automatically add indicators to all variables.
The imputer has the option to add missing indicators to all variables or only to those
that have missing data in the train set. You can change the behaviour using the
parameter missing_only.
If missing_only=True, missing indicators will be added only to those variables with
missing data in the train set. This means that if you passed a variable list to
variables and some of those variables did not have missing data, no missing indicators
will be added to them. If it is paramount that all variables in your list get their
missing indicators, make sure to set missing_only=False.
Tip
It is recommended to use missing_only=True when not passing a list of variables to
impute.
Python implementation#
Below a code example using the house prices dataset.
First, let’s load the data and separate it into train and test:
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from feature_engine.imputation import AddMissingIndicator
# Load dataset
data = fetch_openml(name='house_prices', as_frame=True)
data = data.frame
# Separate into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
data.drop(['Id', 'SalePrice'], axis=1),
data['SalePrice'],
test_size=0.3,
random_state=0)
Now we set up the imputer to add missing indicators to the 4 indicated variables:
# set up the imputer
addBinary_imputer = AddMissingIndicator(
variables=['Alley', 'MasVnrType', 'LotFrontage', 'MasVnrArea'],
)
# fit the imputer
addBinary_imputer.fit(X_train)
Because we left the default value for missing_only, AddMissingIndicator()
will check if the variables indicated above have missing data in X_train. If they do,
missing indicators will be added for all 4 variables looking forward. If one of them
had not had missing data in X_train, missing indicators would have been added to the
remaining 3 variables only.
We can know which variables will have missing indicators by looking at the variable list
in AddMissingIndicator()’s attribute variables_.
Now, we can go ahead and add the missing indicators:
# transform the data
train_t = addBinary_imputer.transform(X_train)
test_t = addBinary_imputer.transform(X_test)
train_t[['Alley_na', 'MasVnrType_na', 'LotFrontage_na', 'MasVnrArea_na']].head()
In the following image, we se the result of the previous code, that is, the missing indicators that were added to the dataframe:
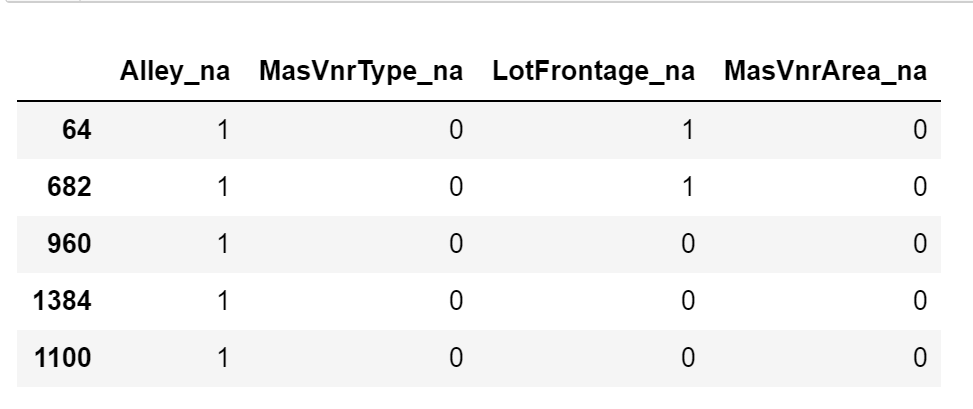
Note that after adding missing indicators, we still need to replace NA in the original variables if we plan to use them to train machine learning models.
Considerations#
Missing indicators are commonly used alongside random sampling, mean or median imputation, or frequent category imputation.
Additional resources#
For tutorials about missing data imputation methods check out these resources:
Feature Engineering for Machine Learning, online course.
Feature Engineering for Time Series Forecasting, online course.
Both our book and courses are suitable for beginners and more advanced data scientists alike. By purchasing them you are supporting Sole, the main developer of Feature-engine.